
what i learned
[ML] 추천시스템(3) - 최근접 이웃 협업 필터링 본문
추천시스템은 크게 콘텐츠기반 필터링과 협업 필터링으로 나뉘게 된다.
[ML] 추천시스템
추천시스템은 크게 콘텐츠 기반 필터링과 협업 필터링으로 나뉜다. 1️⃣ 콘텐츠 기반 필터링 2️⃣ 협업 필터링 ◎ 최근접 이웃 협업 필터링(=메모리 협업 필터링) - 사용자 기반 - 아이템 기반
enddl3224.tistory.com
그 중 협업 필터링인 아이템 기반 최근접 이웃 협업 필터링에 대해 자세히 공부하려고 한다.
최근접 이웃 필터링은 아이템 기반과 사용자 기반이 있는데,
아이템A를 좋아하는 사용자A가 아이템B를 좋아한다고 해서 아이템A를 좋아하는 사용자B에게 아이템B를 추천하여 사용자가 좋아할 확률보다
아이템A를 구매한 사용자B에게 다른 사용자들이 선호했던 아이템B를 추천하는 편이 더 정확도가 높을 것이다.
사용자 기반 협업 필터링

아이템 기반 협업 필터링

이 중 아이템을 기반으로 한 최근접 이웃 협업 필터링을 구현해보려고 한다.
'평점을 매긴 사용자'와 사용자가 매긴 '평점' 데이터가 행렬로 필요하므로 MovieLens데이터셋을 사용하겠다.
MovieLens DataSet Download ➡️ 링크
MovieLens 데이터셋을 사용한 최근접 이웃 협업 필터링(아이템기반)
협업 필터링은 사용자와 아이템 간의 평점에 기반하여 추천하는 시스템이다.
1️⃣ 필요한 데이터로 행렬 생성
먼저, 사용자와 아이템 평점에 기반하기 위해 행렬을 사용자-영화평점 데이터로 변경한다.
(MovieLens 데이터셋은 단순히 userId, movieId, rating 정보가 입력된 데이터이기 때문)

사용자-영화평점 데이터로 행렬을 변환한 뒤 3개의 row만 출력해보았다.
이번 행렬 역시 평가를 하지 않은 사용자들이 많아 0값이 많은 희소행렬이 생성되었다.
2️⃣ 코사인 유사도를 사용하여 영화간 유사도 산출
원하는 데이터 행렬을 얻었으니 영화 간 유사도를 산출하려고 하는데,
코사인 유사도에서 기준이 되는 데이터는 열이 아닌 행을 기준으로 비교하는 것이다.
그렇기 때문에 위에서 얻은 데이터로는 영화간의 유사도가 아닌 사용자와의 유사도를 비교하게 되므로 전치행렬로 변환해준다.

이 후 코사인 유사도를 진행해보면,

영화 간의 유사도를 알 수 있다.
영화 "인셉션"과 가장 유사한 영화 5개를 출력해보면,

다크나이트가 가장 유사도가 높은 영화라는 것을 알 수 있다.
3️⃣ 아이템 기반의 최근접 이웃 협업 필터링을 사용한 추천


위의 예제를 통해 식을 풀어보자면,
인셉션에 대한 사용자1의 예측 평점값은 인셉션과 유사도가 높은 N개의 영화(dark knight:0.727, inglourious basterds:0.646...)들의 유사도 값과 사용자 1이 해당 영화(dark knight, inglourious basterds...)들의 평점을 준 값을 곱한 후 해당 영화들의 유사도 값을 합한 값으로 나눈 값이다.
먼저 N개의 갯수를 지정하지 않고 모든 영화들과 비교해보겠다.

위의 식을 사용해서 평점을 주지 않은 칸에도 예측 값들이 생성된 걸 확인할 수 있다.

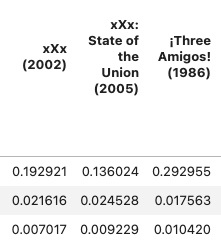
하지만, 예측 사용자 평점 데이터를 만들때, 코사인 유사도 벡터의 합으로 나누었기 때문에 실제 사용자 평점보다 예측된 사용자 평점이 더 작을 수 있다.
(실제 사용자 평점 데이터에 평점을 남기지 않아 0값이 많았기 때문도 있고 코사인 유사도로 결과값을 예측할 때 비교하는 데이터 양이 많아지면 유사도 성능이 떨어지기 때문)
따라서 이 오차를 줄이기 위해 수식에서 사용하는 N을 설정해보겠다.


유사도가 조금 더 올라간 것을 확인할 수 있다.
4️⃣ 예측된 행렬을 통해 사용자에게 영화 추천하기
예측된 행렬을 가지고 사용자에게 영화를 추천하면 끝이다.
사용자1이 남긴 평점을 기준으로 좋아하는 영화를 분석한 뒤, 그 영화들을 기반으로 추천해주면 된다.

사용자1이 좋아할만한 영화 10개를 선별해보았다.

스타워즈와 인디아나존스를 좋아하는 사용자1에게 대부와 다이하드같은 영화가 추천된 것을 볼 수 있다.
위의 실습을 진행한 코드를 자세히 보고 싶다면 ➡️ github.com/enddl3224
학습을 참고한 원본 코드는 ➡️ (링크)파이썬 머신러닝 완벽가이드
"파이썬 머신러닝 완벽 가이드"를 학습하여 기록한 글입니다.
[참고자료]
공부한 내용을 기록하는 공간입니다.
잘못된 정보가 있을 경우 댓글로 피드백 주세요.
올바른 지식을 알려주셔서 감사합니다:)
'Artificial Intelligence > Machine Learning' 카테고리의 다른 글
| [ML] 추천시스템(4) - 잠재요인 협업 필터링 (0) | 2023.12.04 |
|---|---|
| [ML] 코사인 유사도 (0) | 2023.11.19 |
| [ML] 추천시스템(2) - 콘텐츠 기반 필터링 (0) | 2023.11.19 |
| [ML] 추천시스템(1) (1) | 2023.11.16 |
| [ML] Text Classification(2) - Feature Vectorization (0) | 2023.10.13 |



